


Estimer la TVA non recouvrée à partir des contrôles fiscaux
Pour estimer le manque à gagner de l’État lié au non-recouvrement de la TVA, l’Insee s’est appuyé sur les redressements effectivement constatés lors des contrôles fiscaux. Or, les entreprises contrôlées ne sont pas représentatives de l’ensemble des entreprises : elles ont des caractéristiques qui ne permettent pas d’extrapoler directement leur comportement à toutes les entreprises. Pour résoudre au mieux cette difficulté, des techniques issues de la correction des non-réponses dans les enquêtes statistiques ont été mobilisées. Elles s’appuient sur des méthodes d’apprentissage (machine learning) pour déterminer les informations qui ont une incidence sur la probabilité d’être contrôlé. Pour l’exercice comptable 2012, le montant de TVA non recouvrée est estimé entre 20 Md€ et 26 Md€, soit 17 % à 21 % des recettes de TVA cette année-là. Cette estimation reste fragile : par construction, la méthode ne prend pas en compte les comportements frauduleux non détectés par les contrôleurs, ni à l’inverse la possibilité que les contrôleurs aient ciblé des entreprises particulièrement suspectes sur la base d’informations complémentaires à celles qui ont été utilisées dans cet exercice.
L’estimation du manque à gagner de l’État lié au non-recouvrement de l’impôt est un enjeu important du débat public. Ce non-recouvrement correspond à des sous déclarations, que ces dernières soient intentionnelles (fraude) ou non ; dans les estimations, il est impossible de distinguer la fraude de la sous-déclaration « de bonne foi », les deux étant confondues dans les chiffrages. Dissimulée par essence, la fraude ou plus largement la sous-déclaration est en outre difficile à appréhender. C’est pour cet exercice complexe que la Cour des comptes a sollicité l’Insee dans le cadre du rapport sur La fraude aux prélèvements obligatoires publié fin 2019. Elle demandait à l’institut d’estimer les montants manquants de versements de Taxe sur la valeur ajoutée (TVA). Depuis ce premier chiffrage, la méthodologie a été affinée, et les estimations recalculées sont désormais accompagnées d’intervalles de confiance. L’objet de cet article est de présenter succinctement la nouvelle méthodologie et les résultats obtenus, mais aussi les limites qui s’imposent pour leur bonne interprétation (pour une présentation détaillée, voir le document de travail Insee n° 2022/11).
Parmi tous les impôts, la TVA tient une place particulière. D’abord par son poids dans les recettes de l’État : en 2021, elle a rapporté 164 Md€, soit plus du double de l’impôt sur le revenu. Ensuite, par la publication régulière d’évaluations macroéconomiques de « l’écart de TVA » réalisées par la Commission européenne. Cet « écart de TVA » est égal à la différence entre les recettes de TVA attendues, en pratique estimées par application des taux en vigueur aux données des comptes nationaux, et le montant effectivement perçu. Toutefois, ces données ne sont pas forcément disponibles au niveau de détail requis pour appliquer ces taux, et elles ont pu faire l’objet de diverses corrections pouvant les rendre moins pertinentes pour les utiliser à cette fin. Pour contourner ces écueils et estimer au plus près l’ampleur de la fraude à la TVA, une approche empirique apparaît plus pertinente, fondée sur les redressements effectivement notifiés à l’issue des contrôles fiscaux menés par l’administration fiscale (direction générale des finances publiques, DGFiP). Les entreprises contrôlées sont cependant très particulières : elles constituent un « échantillon biaisé » de l’ensemble des entreprises, car les contrôles ne sont pas aléatoires et ciblent les entreprises les plus susceptibles de frauder. La principale difficulté pour extrapoler leur comportement à celui de toutes les entreprises est de réussir à corriger ce biais.
Pour ce travail méthodologique, l’Insee s’est donc appuyé sur ces données qui fournissent les montants de redressement notifiés à chaque entreprise ayant fait l’objet d’un contrôle fiscal pour tout ou partie de l’exercice comptable de l’année 2012 (montants éventuellement nuls si le contrôleur ne constate aucune irrégularité). Pour chaque contrôle fiscal, on connaît le montant total de redressement sur l’ensemble de la période contrôlée, mais pas sa répartition par exercice comptable. Or la période contrôlée peut s’étaler sur quelques mois mais parfois porter sur plusieurs années (ce qui explique qu’il est nécessaire d’avoir suffisamment de recul pour une première estimation). Dans ce dernier cas, attribuer l’ensemble du redressement à l’année 2012 conduirait à surestimer le redressement pour cette année. La part du montant de redressement attribuée à l’année 2012 retenue pour nos estimations est donc obtenue au prorata du nombre de mois d’exercice contrôlés de l’année 2012 sur le nombre total de mois sur lequel le contrôle s’étend.
Tenir compte du processus de sélection
Si la probabilité de chaque entreprise d’être l’objet d’un contrôle fiscal était connue, il serait facile d’extrapoler le manque à gagner observé sur les seules entreprises contrôlées à l’ensemble des entreprises : il suffirait d’attribuer à chaque entreprise contrôlée une pondération (l’inverse de la probabilité d’être contrôlée) rendant compte de son importance ou de son poids dans l’ensemble de la population des entreprises. Comme ce n’est pas le cas, cette probabilité doit être estimée. Pour cela, nous appliquons une méthode inspirée de celles utilisées pour corriger de la non-réponse les données issues d’une enquête statistique, une situation dans laquelle on ne connaît pas non plus la probabilité de répondre. Une telle approche vise à rendre compte du processus de sélection qui a conduit à ce que certaines entreprises soient contrôlées et d’autres pas, de la même façon que l’on tient compte des facteurs qui ont conduit à ce que certains individus répondent à une enquête et d’autres pas dans le cadre du redressement de la non-réponse.
S’agissant du contrôle fiscal, certains éléments du processus de sélection sont connus. Ainsi, de par la finalité dissuasive du contrôle, tous les secteurs d’activité doivent être contrôlés. Dans le même temps, de par leurs finalités budgétaire et répressive, les contrôles ciblent les entreprises les plus susceptibles de se voir notifier des montants importants, afin de recouvrer le plus possible les montants manquants à l’État. Ce ciblage introduit ainsi un biais de sélection dont il s’agit de tenir compte au mieux.
Pour cela, on commence par s’appuyer sur les éléments connus d’organisation de ce ciblage. Le contrôle fiscal est réparti entre plusieurs niveaux d’administration de la DGFiP selon la taille des entreprises, principalement définie à partir du chiffre d’affaires : au niveau national la direction des Vérifications nationales et internationales (DVNI) est chargée des grandes entreprises, notamment des groupes ; au niveau interrégional, les directions spécialisées du contrôle fiscal (Dircofi) se chargent des moyennes entreprises ; et enfin, au niveau local les directions locales des finances publiques s’occupent des plus petites entreprises. En 2012, 2,1 % des entreprises dont le contrôle fiscal est assuré par des directions locales sont contrôlées, tandis que 13 % environ des entreprises dont le contrôle dépend d’une Dircofi ou de la DVNI le sont. Au sein des directions locales, 68 % des entreprises contrôlées font l’objet d’un redressement, contre 58 % lorsque le contrôle est réalisé par une Dircofi et 42 % dans le cas de la DVNI. Enfin, les montants de redressement notifiés sont bien évidemment plus importants lorsque le chiffre d’affaires est élevé, mais plus faibles en proportion de la TVA déclarée. Effectuer des estimations séparées sur ces trois sous-populations d’entreprises permet ainsi de tenir compte des spécificités du processus de sélection des entreprises contrôlées propre à chaque administration fiscale en charge du contrôle.
Prédire les probabilités de contrôle à l’aide du machine learning
Au sein de chaque niveau d’administration, le contrôle d’une entreprise est en effet décidé à partir d’informations variées (absence d’un contrôle récent, informations issues des déclarations fiscales, informations locales, etc.) et s’appuie aussi sur l’expertise des contrôleurs, difficile à formaliser et à généraliser. Il dépend enfin des moyens humains dévolus au contrôle fiscal sur la période considérée. Aussi, en pratique, on mobilise les nombreuses informations disponibles dans les déclarations fiscales pour prédire les probabilités de contrôle de chaque entreprise à l’aide de méthodes d’apprentissage (machine learning). Cette façon de procéder vise à redresser au mieux le biais de sélection dans le contrôle. Les techniques usuelles de redressement de la non-réponse dans les enquêtes préconisent cependant de ne pas utiliser telles quelles ces probabilités calculées individuellement pour chaque entreprise, mais plutôt de constituer des groupes d’entreprises ayant des probabilités estimées de contrôle très proches, appelés groupes de contrôle homogène (GCH), et d’attribuer à toutes les entreprises d’un même GCH la même probabilité de contrôle, calculée tout simplement comme la proportion d’entreprises effectivement contrôlées dans le groupe (Deroyon, 2018 ; Haziza et Beaumont, 2007). In fine, la pondération associée à chaque entreprise est celle associée à son groupe de contrôle homogène et est définie comme l’inverse de la proportion d’entreprises contrôlées dans ce groupe.
Une fois déterminées les pondérations associées à chaque entreprise contrôlée, un estimateur simple du montant de TVA non recouvré pourrait être la somme pondérée (avec les pondérations ci-dessus) des montants de TVA non recouvrés parmi les entreprises contrôlées. Cependant ce type d’estimateur n’est pas le meilleur. On lui a donc préféré deux autres estimateurs, également classiques en théorie des sondages : un estimateur dit « par le ratio » et un estimateur dit « par la moyenne » (cf. document de travail Insee n° 2022/11 pour une présentation plus détaillée de ces deux estimateurs). L’un et l’autre sont plus précis que l’estimateur simple car ils utilisent une information auxiliaire connue sur l’ensemble des entreprises. Ces estimateurs sont construits de telle façon que, si on les utilisait pour estimer la valeur de la variable auxiliaire, ils donneraient la valeur exacte de cette dernière. On espère ainsi que, pour des variables très corrélées avec cette information auxiliaire, il en sera de même ou presque. Pour l’estimateur par le ratio l’information auxiliaire mobilisée est le montant de TVA brute déclarée et pour l’estimateur par la moyenne il s’agit du nombre de mois d’activité.
En 2012, le montant total de TVA non recouvré serait compris entre 20 Md€ et 26 Md€
Quel que soit l’estimateur retenu, les estimations du montant total de TVA non recouvré seraient comprises entre 20 Md€ et 26 Md€, soit 17 % à 21 % des recettes de TVA cette année-là. Le graphique représente ces résultats, obtenus sous différentes hypothèses, et permet d’appréhender l’importance de la prise en compte du ciblage des entreprises contrôlées sur les estimations proposées. Le premier couple d’estimations (une pour chaque estimateur), dites « naïves », considère qu’au sein de chacune des trois administrations en charge du contrôle (DVNI, Dircofi et directions locales), les entreprises contrôlées ont été choisies au hasard avec la même probabilité, c’est-à-dire sans tenir compte du processus de sélection effectué par chaque administration. Le couple d’estimations suivantes, dites « redressées », considère que les entreprises ont des probabilités d’être contrôlées différentes, correspondant à celles estimées avec la méthode présentée ci-dessus, c’est-à-dire à partir des groupes de contrôle homogène. Le dernier couple d’estimations, dites « redressées par secteur » s’appuie sur ces mêmes probabilités, mais procède à des estimations par secteur d’activité ce qui permet de tenir compte d’informations auxiliaires plus détaillées (pour chaque secteur) et rend l’estimateur plus précis, en intégrant de fait les différences moyennes par secteur de comportement frauduleux.
Figure 1 – Montants manquants de TVA estimés par la moyenne et par le ratio
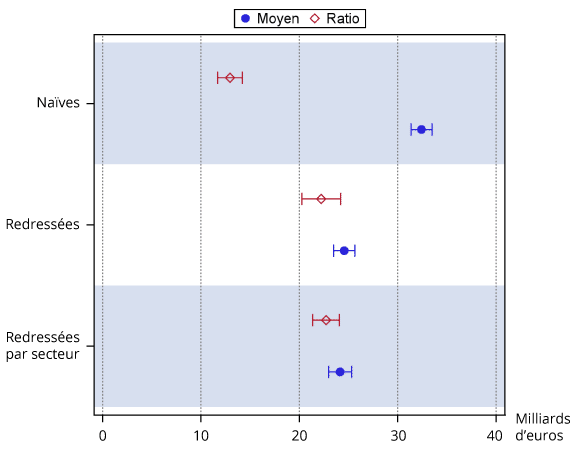
Les diverses méthodes redressées conduisent à des évaluations peu différentes les unes des autres. À l’inverse, elles s’écartent de façon assez marquée de l’approche « naïve ». Cela témoigne de l’importance du processus de sélection des entreprises contrôlées et de la nécessité de sa prise en compte, même si la méthode retenue n’assure pas que l’on a effectivement éliminé la totalité du biais en résultant. Par ailleurs, quelle que soit la spécification retenue, les estimations par le ratio sont plus faibles que les estimations par la moyenne, mais cet écart n’est pas significatif dès lors que l’on tient compte du processus de sélection.
Les estimations présentées dans cette note sont plus élevées que celles annexées au rapport de la Cour des comptes de décembre 2019, qui mentionnait une quinzaine de milliards d’euros, tout en en soulignant l’incertitude. Ces nouvelles estimations utilisent une mesure plus précise du nombre de mois effectifs de contrôle et prennent mieux en compte le processus de sélection des entreprises contrôlées. Ces modifications conduisent à rehausser les estimations.
Des limites importantes à ces estimations
Ces estimations sont cependant à manier avec prudence, et il convient de garder à l’esprit plusieurs limites importantes. D’abord, les méthodes d’apprentissage utilisées pour prédire les probabilités de contrôle restent imparfaites. La prise en compte du processus de sélection à partir des caractéristiques observées disponibles est donc probablement incomplète. En particulier, cette démarche ne peut pas rendre compte des déterminants inobservés du contrôle, comme, par exemple, l’expertise des contrôleurs fiscaux dans l’arbitrage entre deux entreprises à contrôler, faute de moyens. Le biais de sélection ne peut donc qu’être partiellement corrigé, et il n’est pas possible de connaître l’ampleur du biais résiduel. Enfin, les redressements prononcés à l’encontre des entreprises contrôlées résultent de la détection par le contrôleur fiscal d’une irrégularité ou d’un comportement frauduleux. En s’appuyant sur les résultats des contrôles menés par la DGFiP, notre estimation fait donc implicitement l’hypothèse que les irrégularités commises par les entreprises sont toutes détectées par les services fiscaux lors du contrôle. En cela, notre estimation ne prend pas en compte les comportements frauduleux non détectés par le contrôleur fiscal. S’il n’apparaît pas possible de corriger ce biais dit de détection, la mise en place de contrôles aléatoires permettrait d’améliorer la prise en compte du biais de sélection. ■
Pour en savoir plus
- Beaumont J-F. et Haziza D., 2007, « On the Construction of Imputation Classes in Surveys », International Statistical Review Vol. 75, n° 1, pp. 25-43, avril
- Cour des comptes, 2019, « La fraude aux prélèvements obligatoires – Évaluer, prévenir, réprimer », Rapport au premier ministre, décembre.
- Deroyon T., 2017, « La correction de la non-réponse par repondération », note méthodologique, octobre
- DGFIP, 2022, « La taxe sur la valeur ajoutée en 2021 », DGFIP Statistiques n° 11, septembre
- Quantin S. et Welter-Médée C. , 2022, « Estimation des montants manquants de versements de TVA : exploitation des données du contrôle fiscal », document de travail Insee n° 2022/11, juillet
Crédits photo : © MQ-Illustrations © LChevret – stock.adobe.com



