


Comment l’Insee protège-t-il les données qu’il collecte ?
De la collecte à la diffusion, l’Insee et chacun de ses agents, comme l’ensemble des agents du service statistique public, s’attachent à respecter un engagement fort vis-à-vis de la société : celui de protéger les données qu’ils traitent.
Ils s’appuient à la fois sur un cadre légal qui fixe des obligations en termes de protection ou de traitement des données collectées, sur des valeurs professionnelles fortement ancrées, sur des systèmes d’information et de communication sécurisés et régulièrement audités, ainsi que sur des procédures de pseudonymisation (suppression la plus précoce possible des noms et prénoms des personnes) puis d’anonymisation (il devient impossible de relier une donnée à la personne qu’elle concerne).
Lors de la diffusion des données, différentes méthodes de gestion du secret statistique sont mises en œuvre.
Dans tous les cas, la mise à disposition des données auprès du public ou des chercheurs vise à garantir la protection du secret statistique et plus généralement la protection des données à caractère personnel, tout en permettant la richesse des usages.
La matière première des statistiques, ce sont les données. Ces données, l’Insee les collecte de plusieurs manières (Dupont, 2023) : par voie d’enquêtes auprès des ménages ou des entreprises, c’est la forme la plus visible, ou bien en réutilisant des données déjà collectées par des administrations, ou encore, plus récemment, en accédant à des données collectées par des acteurs privés (Biau et al., 2024).
Quelle que soit la manière dont l’Insee rassemble ces données, elles ont un point commun : l’institut se doit de les protéger de toute diffusion qui porterait préjudice aux personnes ou entreprises concernées, ou de toute utilisation de ces données à des fins illégitimes (Redor, 2023). C’est une obligation légale, fondée sur la loi de 1951 sur l’obligation, la coordination et le secret en matière statistique et sur la loi Informatique et libertés de 1978, ainsi que sur le Règlement général sur la protection des données (RGPD) pris au niveau européen.
Mais c’est aussi une affaire de principes. Parmi les principes déontologiques fondamentaux des statisticiens publics figure en effet celui du respect de la vie privée, qui impose notamment de ne pas divulguer d’informations confidentielles portant sur les individus, et plus largement celui de la protection de tous les secrets qui s’attachent aux données collectées et traitées. Chaque agent de l’Insee, et plus largement chaque agent du service statistique public, signe dès sa prise de poste un engagement à respecter ce secret et il est régulièrement sensibilisé à ses obligations en la matière, qu’il s’agisse de ne pas divulguer les données dont il a connaissance ou de les protéger.
Une fois ces obligations et principes posés, comment l’Insee procède-t-il concrètement pour protéger ces données de toute utilisation illégitime ?
Un principe essentiel du droit de la statistique : le respect du secret
Un premier rempart qui a donné en partie son nom à la loi de 1951 est d’ordre juridique : quel que soit le demandeur, le service statistique public a l’interdiction de retransmettre des données individuelles collectées à des fins statistiques. Par exemple, ces données ne peuvent donc être transmises ni aux impôts, ni aux organismes de sécurité sociale, ni à la police. Au-delà des données provenant de la collecte, cette protection s’applique également aux données statistiques issues de traitements qui permettraient, par recoupements, d’identifier telle personne ou telle entreprise à partir de l’information diffusée. C’est ce que l’on appelle le secret statistique.
Le secret statistique est opposable à toute demande externe, même émanant d’une autorité judiciaire. En cas de violation du secret statistique, le statisticien public s’expose à des sanctions pénales pouvant aller jusqu’à un an d’emprisonnement et 15 000 € d’amende.
Les seules exceptions concernent les données demandées pour des motifs statistiques ou de recherche scientifique ou historique ; l‘opportunité de ces demandes fait l’objet d’un examen spécifique et, si la demande est validée et les données individuelles effectivement transmises, l’obligation de respecter le secret s’applique au destinataire.
Toutefois, même si l’Insee ne veut ni ne peut diffuser ces données confidentielles, il convient de se prémunir contre tout risque de fuite ou violation de données. Cela relève de plusieurs actions complémentaires, permettant d’assurer une protection renforcée des données : cela vise l’impossibilité d’accéder à une donnée pour un agent de l’Insee qui n’y est pas habilité, mais aussi à empêcher d’associer une donnée (par exemple un revenu, une nationalité, un chiffre d’affaires) à une personne ou une entreprise en particulier.
Flux sécurisés, coffres-forts de données, gestion stricte des droits d’accès …
Sur un plan technique, les outils informatiques de collecte, mais également de traitement ou diffusion de données, font l’objet d’une attention particulière, visant à éviter tout risque qu’une personne non autorisée prenne connaissance de données confidentielles, voire puisse en extraire du système d’information de l’Insee ou les modifier. Il s’agit de respecter un ensemble de règles de sécurité et d’intégrité des systèmes d’information, édictées par l’Agence nationale de la sécurité des systèmes d’information (Anssi) ; et pour les systèmes gérant des données particulièrement sensibles, de prendre en plus des dispositions spécifiques de protection.
Tout ceci vise à garantir que les coffres-forts numériques dans lesquels sont stockées les données sont inviolables, que leur accès est strictement contrôlé et limité aux seuls agents habilités, que les circuits par lesquels transitent les données sont eux aussi sécurisés : par exemple, une donnée collectée par internet l’est selon un protocole sécurisé de type https.
Les dispositifs de l’Insee qui collectent, traitent et mettent à disposition ces données font l’objet de procédures régulières d’homologation de sécurité, visant à vérifier que leur niveau de sécurité est bien conforme aux enjeux de confidentialité et d’intégrité. Et l’ensemble du système d’information de l’Insee fait l’objet d’une surveillance continue pour vérifier l’absence de cyber-attaque ou de tentative de compromission des fichiers.
De plus, les traitements de données respectent le principe de minimisation, qui consiste à ne collecter que les données nécessaires à la finalité poursuivie et à ne les conserver que tant qu’elles sont indispensables pour cette finalité. Enfin, les données sont segmentées, c’est-à-dire qu’elles sont organisées sous forme de fichiers séparés, conservés dans des coffres-forts distincts, et qui ne sont mis en relation que pour une finalité donnée.
Parallèlement à ces dispositions, les habilitations sont très restrictives : un agent de l’Insee n’a le droit d’accéder qu’aux données nécessaires à l’exercice de ses missions et ses droits sont revus dès qu’il change de poste.
Casser le lien entre la donnée et son « porteur » : de la pseudonymisation à l’anonymisation
Mais ce n’est pas tout : l’Insee ne se contente pas d’enfermer les données et de gérer rigoureusement les clés des coffres, il s’attache, pour les données à caractère personnel qu’il collecte, à rompre le lien entre les données et l’identité des personnes. L’enjeu est de ne plus pouvoir relier une donnée collectée (une nationalité, un revenu) à la personne, ou aux personnes, à laquelle elle se rapporte.
Pour cela, une première étape est d’effacer le plus tôt possible les données directement identifiantes, en les remplaçant par des identifiants techniques, non signifiants, utilisés uniquement à l’intérieur de l’Insee. Il en résulte qu’on ne peut deviner ou retrouver aucune des caractéristiques de la personne au vu de son identifiant : c’est ce que l’on appelle la pseudonymisation.
En d’autres termes, Olivier Lefebvre habitant au 88 avenue Verdier à Montrouge devient BZ34R&T habitant à l’adresse Cf45ZT8* (figure 1). Si on ouvre un fichier statistique où figure Olivier Lefebvre, il n’apparaîtra pas sous son vrai nom et on ne le reconnaîtra pas immédiatement. La donnée qui le concerne existe dans nos fichiers, mais on ne peut plus la rapprocher facilement de son « porteur ».
Cette opération est effectuée dès que l’on n’a plus besoin des noms, prénoms, adresses, qui sont utiles lors de la phase de collecte de l’information, par exemple pour vérifier que telle personne ou telle entreprise de l’échantillon a bien répondu à l’enquête, ou que l’on a bien les données qui la concernent dans la source administrative que l’on traite.
Ainsi débarrassée de ses étiquettes directement identifiantes, la donnée est beaucoup moins sensible.
Mais il arrive que cette précaution ne suffise pas : il est en effet parfois possible de reconnaître une personne à partir de ses caractéristiques, même si on n’a plus son nom et son prénom. Par exemple, s’il y a un seul médecin dans la commune, il est facile de le reconnaître si le fichier comporte la profession et la commune de résidence. Pour pallier ce risque, on s’appuie sur des niveaux agrégés de nomenclature : le médecin sera décrit comme cadre et on indiquera son département de résidence et non pas sa commune de résidence ; ou bien, si l’on veut conserver une description fine des professions, on ne donne aucune information géographique en deçà d’une zone de résidence de taille suffisante, comme la région ou le département.
On parle alors d’anonymisation : il est impossible, en utilisant des moyens raisonnables, de reconnaître une personne à partir des seules données présentes dans le fichier.
Figure 1 – De la pseudonymisation à l’anonymisation
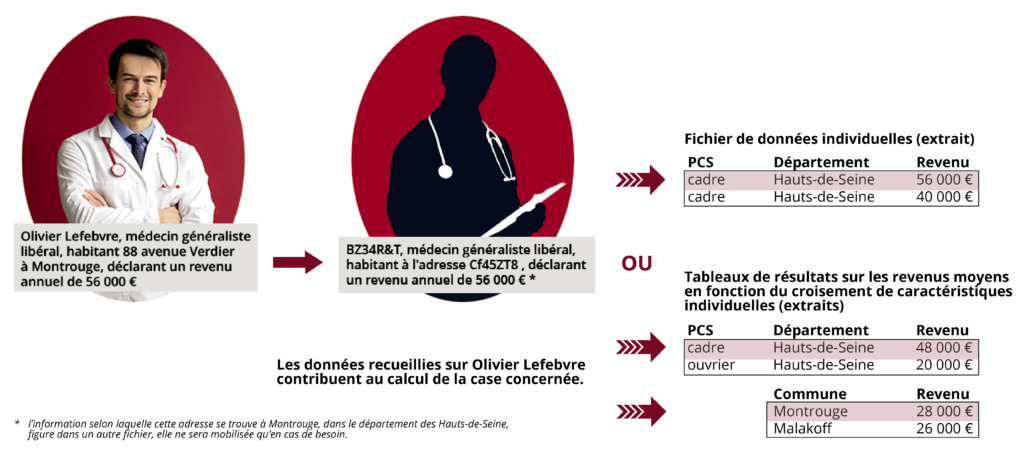
Olivier Lefebvre, médecin généraliste libéral, habitant 88 avenue Verdier à Montrouge, déclarant un revenu annuel de 56 000 € devient :
BZ34R&T, médecin généraliste libéral, habitant à l’adresse Cf45ZT8 (l’information selon laquelle cette adresse se trouve à Montrouge, dans le département des Hauts-de-Seine, figure dans un autre fichier, elle ne sera mobilisée qu’en cas de besoin), déclarant un revenu annuel de 56 000 € (étape de pseudonymisation)
puis : une ligne d’un fichier désignant un cadre, habitant les Hauts-de-Seine, déclarant un revenu annuel de 56 000 € (étape d’anonymisation)
ou : un composant de la case du tableau donnant le revenu moyen des cadres des Hauts-de-Seine, ou de la case donnant le revenu moyen des habitants de Montrouge.
La diffusion de données agrégées : une affaire d’équilibre
Les données agrégées, ce sont des comptages ou des cases de tableau résultant du traitement des données. Il s’agit donc de nombres et pas de données individuelles. Ces nombres peuvent être utilisés pour eux-mêmes (la population des 15-24 ans d’Île-de-France, le taux de chômage en Auvergne-Rhône-Alpes) ou comme « briques » pour constituer une statistique sur un champ défini par l’utilisateur. Pour que le champ puisse être délimité le plus précisément possible, qu’il s’agisse d’un critère d’âge, de catégories sociales ou d’un critère géographique, il est préférable de diffuser les briques les plus fines possibles, tant qu’elles sont compatibles avec les obligations du secret.
L’intérêt de diffuser l’information à une maille très fine n’est pas de regarder chacune des briques, mais de permettre à l’utilisateur de reconstituer ses propres périmètres d’intérêt. Par exemple, en matière d’analyse des territoires, c’est indispensable afin de mesurer l’impact d’une mesure politique à un niveau très fin ou d’estimer le nombre de personnes soumises à un risque naturel : une zone inondable, une zone de chalandise, un périmètre d’aménagement du territoire, une zone de la carte scolaire….
Pour la diffusion de données agrégées, l’Insee applique des règles relatives à la taille minimale des croisements réalisés. Ainsi, une case de tableau concernant les entreprises doit impérativement comporter au moins trois entreprises et aucune d’entre elles ne doit représenter à elle seule plus de 85 % de l’agrégat représenté. Des dispositions spécifiques peuvent être prises dans le cas des situations de monopole ou duopole, en accord avec les entreprises concernées.
Pour les personnes physiques, la taille minimale est de cinq personnes, à l’exception des statistiques s’appuyant sur des données fiscales où elle est portée à onze foyers fiscaux.
La limite de cette approche est qu’elle rend très difficile la diffusion d’informations finement localisées, à la commune, au quartier pour les grandes communes ou au carreau (maillage géométrique consistant à découper le territoire zones de 1 km de côté, voire de 200 m de côté, s’affranchissant des limites administratives). En effet, les zones ou cases de tableau d’effectifs trop faibles ne sont pas diffusables (ce que l’on appelle le secret primaire) et les zones qui les englobent peuvent l’être également si elles ne comportent qu’une seule zone non diffusable, qui serait alors reconstituée par différence entre les unités diffusables et le total (ce que l’on appelle le secret secondaire). Le tableau ou la carte seront donc incomplets.
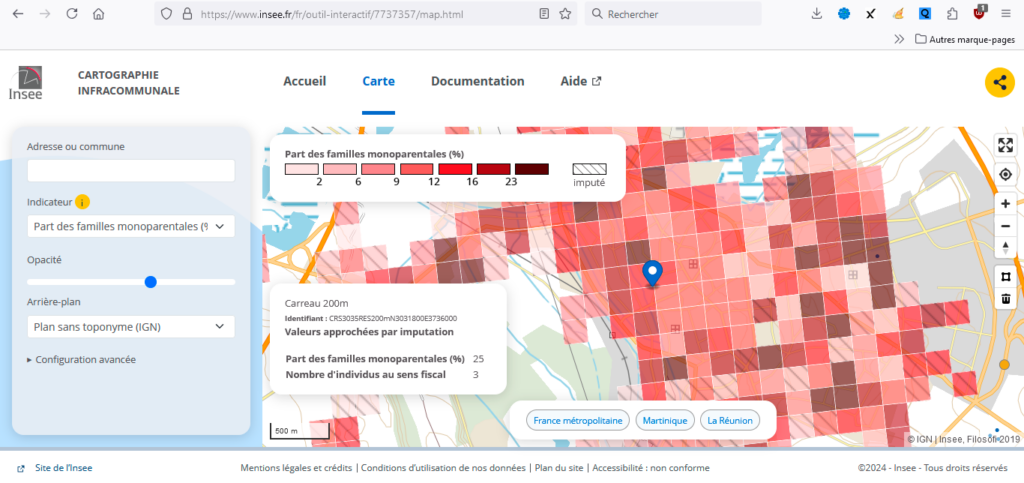
La deuxième approche, pratiquée actuellement par exemple pour la diffusion de données portant sur les niveaux de vie, consiste à agréger une zone non diffusable à une de ses voisines, de façon à respecter les contraintes de diffusion sur la zone ainsi constituée. Les données moyennes calculées sur cette zone agrégée seront reportées sur chacun des carreaux qui la constituent ; on sera donc en présence de données imputées, ne permettant pas de ré-identifier les personnes, tout en préservant la qualité de l’information agrégée.
Figure 2 – Exemple de diffusion de valeurs approchées par imputation
L’Insee commence à mettre en œuvre une troisième méthode, dite « perturbatrice », qui consiste à modifier les données individuelles, sans que cela ne perturbe trop les totaux ou les ratios relatifs à une zone donnée. Concrètement, cela consiste à leur affecter un aléa qui va les modifier, donc rendre impossible l’identification de personnes à partir de cases de faible effectif, mais sans influence significative sur la précision des données statistiques produites. C’est la méthode des clés aléatoires, décrite dans un billet de blog récent (Chevalier, Hachid, Jamme, 2025).
À quelles conditions peut-on diffuser des données individuelles ?
Pour certaines analyses, les données agrégées se révèlent insuffisantes, soit parce que l’utilisateur souhaite effectuer ses propres tabulations, soit parce qu’il veut créer ses propres variables, ou utiliser des méthodes d’analyse de type économétrique (analyses « toutes choses égales par ailleurs », modélisation de comportements) qui reposent sur des données individuelles.
Si le fichier de données est anonymisé, il peut être mis à disposition des utilisateurs externes, puisqu’il ne permet plus de remonter aux personnes. Mais, on l’a vu, cela impose une réduction de l’information disponible, qui peut rendre impossibles certains travaux.
Le législateur a donc prévu une exception, pour des travaux de production de statistiques publiques, de recherche ou d’évaluation de politiques publiques. Sur la base de la finalité du projet qui est mené à partir des données demandées, de la proportionnalité de la demande vis-à-vis du projet, de la qualité du demandeur et avec engagement pour ce dernier de respecter le secret statistique, l’accès à un fichier de données individuelles peut être autorisé après avis du Comité du secret statistique. Cela concerne environ 600 projets de recherche par an (nouveaux projets ou demandes complémentaires pour des projets déjà acceptés). Cet accès se fait alors dans des conditions qui garantissent la plus complète confidentialité des données, par exemple dans un et selon des procédures qui visent à garantir que la personne qui accède aux données est bien habilitée pour cela et qu’elle ne peut exporter que des résultats ne permettant aucune ré-identification ou, s’il s’agit de données agrégées, respectant les règles du secret statistique. ■
Pour en savoir plus
- Chevalier M., Hachid A., Jamme J., 2025 : « Données sur les Quartiers prioritaires de la politique de la ville (QPV) : une nouvelle méthode pour protéger le secret statistique », Blog de l’Insee, janvier
- Union européenne, 2024, Règlement (UE) 2024/3018 du Parlement européen et du Conseil du 27 novembre 2024 modifiant le règlement (CE) n° 223/2009 relatif aux statistiques européennes, novembre
- Biau O., Joubert M-P., Lévy D., 2024, « Grâce à l’Union européenne, davantage de données pour les décideurs publics », Blog de l’Insee, mai
- Redor P., 2023, « Confidentialité des données statistiques, un enjeu majeur pour le service statistique public », Courrier des statistiques n° 9, juin
- Dupont F., 2023, « Quels types de sources l’Insee utilise-t-il pour construire ses statistiques ? », Blog de l’Insee, mai
- Gadouche K., 2019, « Le Centre d’accès sécurisé aux données (CASD), un service pour la data science et la recherche scientifique », Courrier des statistiques n° 3, décembre.
- Cnil, 1978, Loi n° 78-17 du 6 janvier 1978 relative à l’informatique, aux fichiers et aux libertés
- Loi n° 51-711 du 7 juin 1951 sur l’obligation, la coordination et le secret en matière de statistiques
Crédits photo : ©batjatek ©Pixel-Shot ©vertorfusionart – stock.adobe.com



